
Imagine you have a really smart friend who knows a lot about different things. But sometimes, even your friend needs to look things up in a book or online to get the most accurate information.
That’s kind of like what RAG pipelines do for computers. They help computers access and use information from the real world, just like your friend uses books and websites.
By combining the knowledge stored in books and websites with the computer’s own intelligence, RAG pipelines can provide more accurate and informative answers to questions.
Understanding the Need for RAG Pipelines:
You really smart friend who can write stories, translate languages, and answer questions based on what they already know. But sometimes, even your friend needs to check a book or search online to get the most accurate information.
That’s what Large Language Models (LLMs) are like. They’re super smart computers that can do amazing things with language, but sometimes they need to “look things up” in the real world to be fully accurate.
RAG pipelines are like giving your friend a giant library and a super-fast way to find the right book. This way, your friend can combine their own knowledge with information from the library to give you even better answers.
RAG pipelines help computers access and use real-world information, leading to more accurate and informative responses.
The Core Components of a RAG Pipeline:
A typical RAG pipeline consists of two distinct phases:
1. Data Indexing:
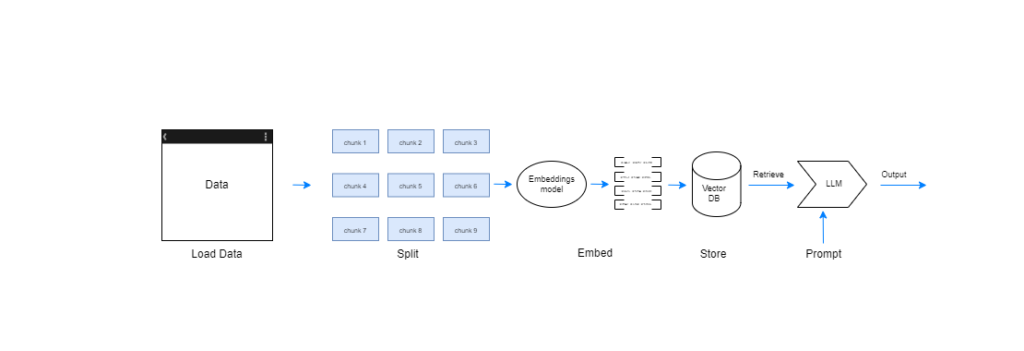
Data Loading:This stage involves gathering relevant documents or information from external sources like Wikipedia, news articles, or domain-specific databases.Data Splitting:Large documents are often segmented into smaller, more manageable units, such as paragraphs or sentences.Data Embedding:Each data segment is converted into a vector representation using an embedding model. This allows efficient comparison and retrieval based on semantic similarity.Data Storing:The generated vector representations are stored in a specialized database, often a vector database, optimized for fast retrieval based on similarity searches.
2. Retrieval & Generation:
Query Processing:When a user submits a question or prompt, the RAG pipeline processes it, generating an initial embedding using the same embedding model employed for the indexed data.Retrieval Stage:The query embedding is compared against the stored document embeddings within the vector database. This retrieves a set of relevant documents with high semantic similarity to the query.Generation Stage:The retrieved documents are passed to the LLM, which leverages its vast internal knowledge and the retrieved context to generate a comprehensive and informative response.
Benefits of Utilizing RAG Pipelines:
RAG pipelines offer several advantages over traditional LLM-based approaches:
Enhanced Factuality:By incorporating external knowledge, RAG pipelines enable LLMs to access and utilize relevant information, leading to more accurate and factual responses.Improved Contextual Understanding:The retrieved documents provide additional context for the LLM, allowing it to generate responses that are more relevant to the specific query and domain.Knowledge Base Expansion:RAG pipelines allow for continuous knowledge base expansion by incorporating new documents and information over time, keeping the system up-to-date.Domain-Specific Adaptability:By tailoring the data sources and retrieval strategies, RAG pipelines can be customized for specific domains, leading to more specialized and accurate responses.
Real-World Applications of RAG Pipelines:
The versatility of RAG pipelines has led to their adoption across various domains:
Chatbots and Virtual Assistants:RAG-powered chatbots can provide more informative and contextually relevant responses, enhancing user interactions.Question Answering Systems:RAG pipelines can significantly improve the accuracy and factual basis of answers provided by question-answering systems.Content Summarization:By leveraging retrieved documents, RAG pipelines can generate more comprehensive and informative summaries of factual topics.Document Search and Retrieval:RAG-based systems can efficiently retrieve relevant documents based on user queries, streamlining information access.
Challenges and Future Directions of RAG Pipelines:
While RAG pipelines offer significant benefits, they also present certain challenges:
Data Selection and Preprocessing:Choosing the appropriate data sources and preparing them effectively plays a crucial role in the pipeline’s performance.Retrieval Efficiency:Optimizing the retrieval process to ensure fast and accurate document selection is essential for real-time applications.Evaluation and Optimization:Developing robust metrics for evaluating RAG pipelines and continuously fine-tuning them for optimal performance is crucial.
.
Conclusion:
RAG pipelines represent a significant advancement in NLP, bridging the gap between the vast knowledge stored in external data and the powerful processing capabilities of LLMs. By combining the strengths of both, RAG pipelines pave the way for more factual, informative, and contextually aware AI systems that can truly understand and respond to user queries in a meaningful way. As research continues to explore the full potential of RAG pipelines, we can anticipate exciting developments that will further reshape the landscape of NLP and its applications across various sectors.
This blog marks the beginning of a series where we will delve deeper into the practical implementation of RAG pipelines using LangChain, a powerful NLP library. Stay tuned for upcoming articles that will guide you through building and utilizing RAG pipelines for your own NLP projects!




